
Objectives :
- Learn the fundamentals of databases, how to design, maintain and secure a database.
Databases

The Problem
As some point, if you're developing an application, you'll need to pause, and reflect on the right approach to store/retrieve/protect the data persisted.
As illustrated in the following diagram, before starting to implement anything, you need to understand the trade-offs, ask yourself these questions :
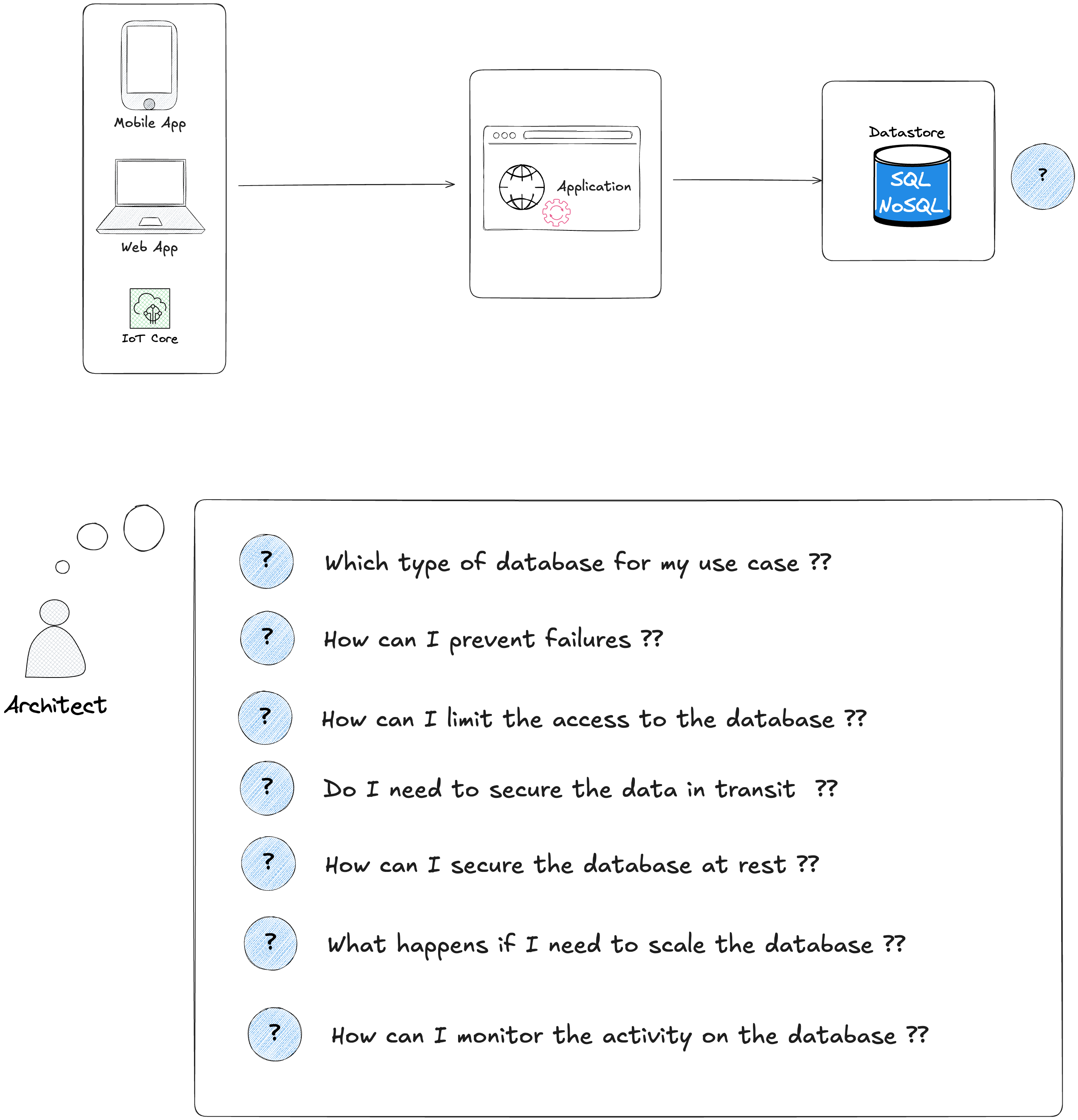
Choosing the right database will impact the performance of your application, so it's important to understand which type of databases are the most appropriate for your use case.
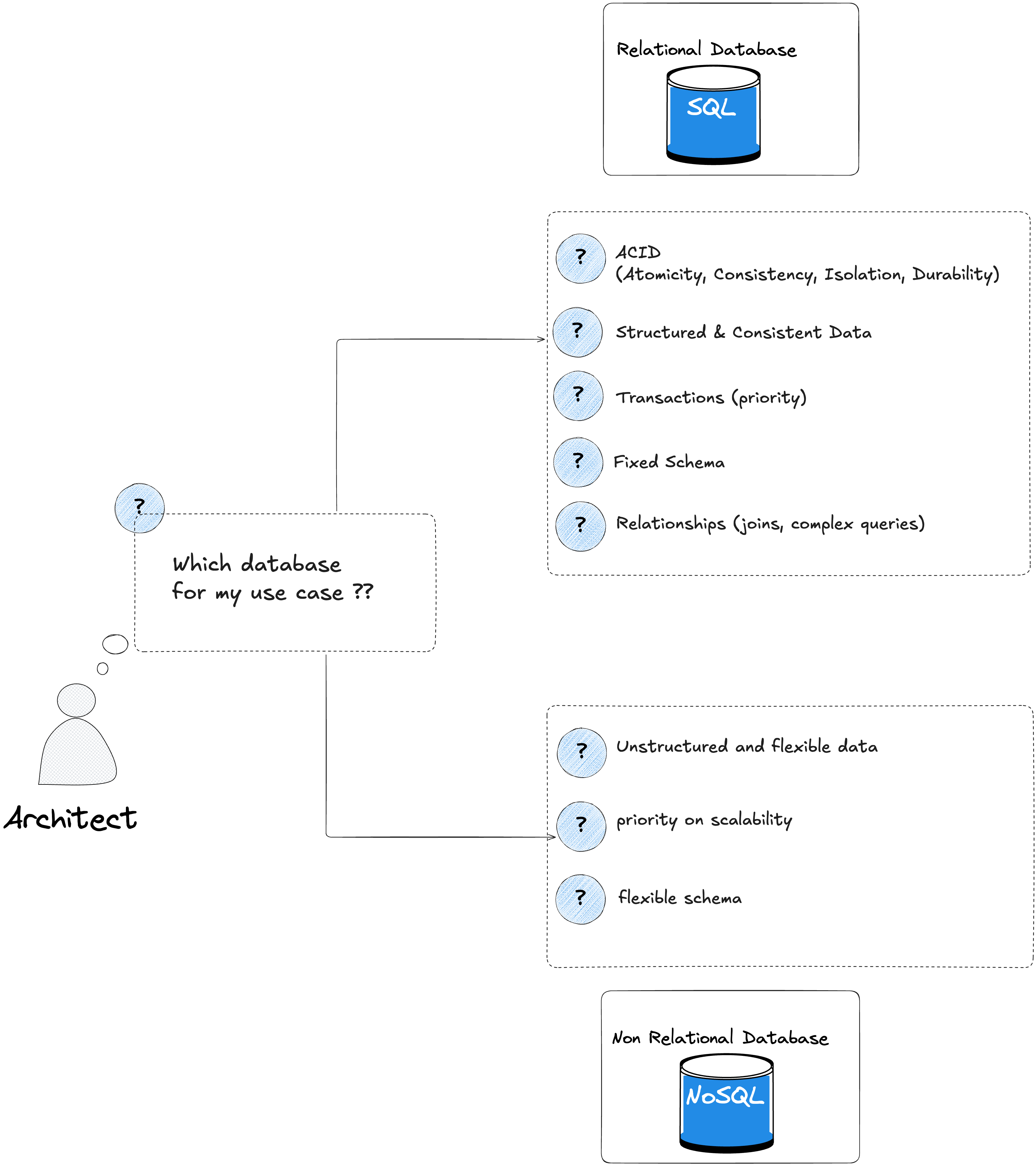
Which type of databases for my use case ?
Your application might be a monolith or microservices, either way, the structure of the data persisted might be more efficient for some services and not for others. You often have to choose between 2 main type of databases :
Relational Database (SQL)
Non-Relational Database (NoSQL)
Relational Database (SQL)
Relational databases are the most common database used by professionals. The main advantage is to provide strong consistency for your application.
Relational databases offer ACID properties : Atomicity, Consistency, Isolation and Durability.
One other aspect, is that relational database require a schema (fixed structure before storing data), this provides more control on the type of data your application persist.
If you need strong relationship (a query to join multiple tables, etc ..), relational database are the most appropriate choice.
To summarize, if your application require the following, you may choose a relational database (SQL):
ACID properties
Data needs to be structured and consistent
The transactions are a strong priority
You have to perform complex queries between data (joins, etc..)
You need in advance to set a fixed schema (structure of the data persisted)
Customers table in a SQL database
| CustomerID | FirstName | LastName | Email |
|------------|-----------|----------|------------------------|
| 101 | Bob | Smith | bob.smith@email.com |
| 102 | Alice | Johnson | alice.j@email.com |
| 103 | John | Doe | john.doe@email.com |
Students table
| StudentID | Name | Age | GPA | GraduationYear |
|-----------|--------------|-----|------|----------------|
| S001 | Daniel Monto | 20 | 3.7 | 2026 |
| S002 | Emma Brown | 22 | 3.9 | 2024 |
| S003 | Liz Brian | 21 | 3.5 | 2025 |
Use-case 1 (Financial industry) : If you develop an application for the financial sector, there is chance that you may want to choose a relational database, for strong consistency , to prevent double spending or balances. You may also have to perform complex queries between customers, accounts and transactions.
Use-case 2 (Ecommerce platform) : If you develop an ecommerce application, you probably need to have a structured data to store your products, categories, customers, orders or reviews. You may need to perform complex queries between the customer and the orders, and you need to guarantee transactions (strong consistency) to ensure a reliable inventory management or checkout.
Use-case 3 (Healthcare systems) : If you develop a healthcare application, and as you store sensitive data, you probably need strong consistency, and integrity. Also, healthcare industries are heavily regulated, so having a relational database will ensure your data persisted follow the latest compliance and regulations.
Non-Relational Database (NoSQL)
Non-Relational databases offer more flexibility. You don't need to have strong consistency and you don't need a fixed schema before storing your data. NoSQL databases are more appropriate for use cases where you need to store unstructured or semi-structured data (JSON Document, Key Value), and you think about having lower latency.
| Types of unstructured data | Examples |
|---|---|
| Text documents | Emails, chat messages, Word/PDF files |
| Media files | Images, videos, audio recordings |
| Social media posts | Tweets, comments, likes |
| Logs & event data | Server logs, clickstreams, IoT device messages |
| Web pages | HTML content with mixed text, links, metadata. |
JSON Document
[
{
"user_id": 123,
"name": "Alice",
"purchases": ["Book", "Laptop", "Headphones"],
"last_login": "2025-09-14"
},
{
"user_id": 124,
"name": "Bob",
"purchases": ["Book", "Laptop", "Headphones"],
"last_login": "2025-09-14"
},
{
"user_id": 125,
"name": "John",
"purchases": ["Book", "Laptop", "Headphones"],
"last_login": "2025-09-14"
}
]
NoSQL databases are a good choice, if you don't want to deal with strict rules to manage your data and the transactions.
To summarize, if your application require the following, you may choose a non-relational database (NoSQL):
Unstructured or semi-structured data, and it's flexible
You expect a huge volume of data, and you don't want to worry about horizontal scaling
You need to have a simple design, with the potential to scale fast.
Use-case 1 (Real-time analytics and Big Data) : You develop an application, at some point you may need to understand more about the users behavior and activity, this will create a huge volume of data (logs, clickstreams, ...), the best way is to use NoSQL databases to handle these type of data (unstructured and semi-structured). Also choosing a non-relational database, is a better option for faster writes and horizontal scaling.
Use-case 2 (Content Management & Product Catalog) : You develop a content management application, or you need to store product catalogs. The content often changes (flexible schema), using JSON documents to store these type of data is more efficient.
Real world companies - use cases
| Company | Database used | Use Case | Estimated Daily Active User (DAU) | Sources |
|---|---|---|---|---|
| Stripe | PostgreSQL + Redis | PostgreSQL for transactional payment data (ACID compliance critical), Redis for caching & real-time fraud detection | ~1.3 million active websites using Stripe globally | https://redstagfulfillment.com/how-many-payments-stripe-process-per-day/ |
| Notion | PostgreSQL + Redis | PostgreSQL for document + collaboration metadata storage, Redis for session caching and quick lookups | ~20M monthly active users | https://www.boringbusinessnerd.com/top-startups? |
| Canva | PostgreSQL + Redis | PostgreSQL for design assets and user accounts, Redis for fast retrieval of frequently accessed templates | ~100M monthly active users | https://www.boringbusinessnerd.com/top-startups? |
| Slack | MySQL, PostgreSQL, Redis | MySQL/Postgres for message history & team data, Redis for ephemeral data (presence, typing indicators) | ~42–47M daily active users | https://www.demandsage.com/slack-statistics/? |
How can I prevent failures ?
Your database is by default in a healthy state, all operations (connections, queries) return a successfull response. But you may experience unexpected downtime due to failures .
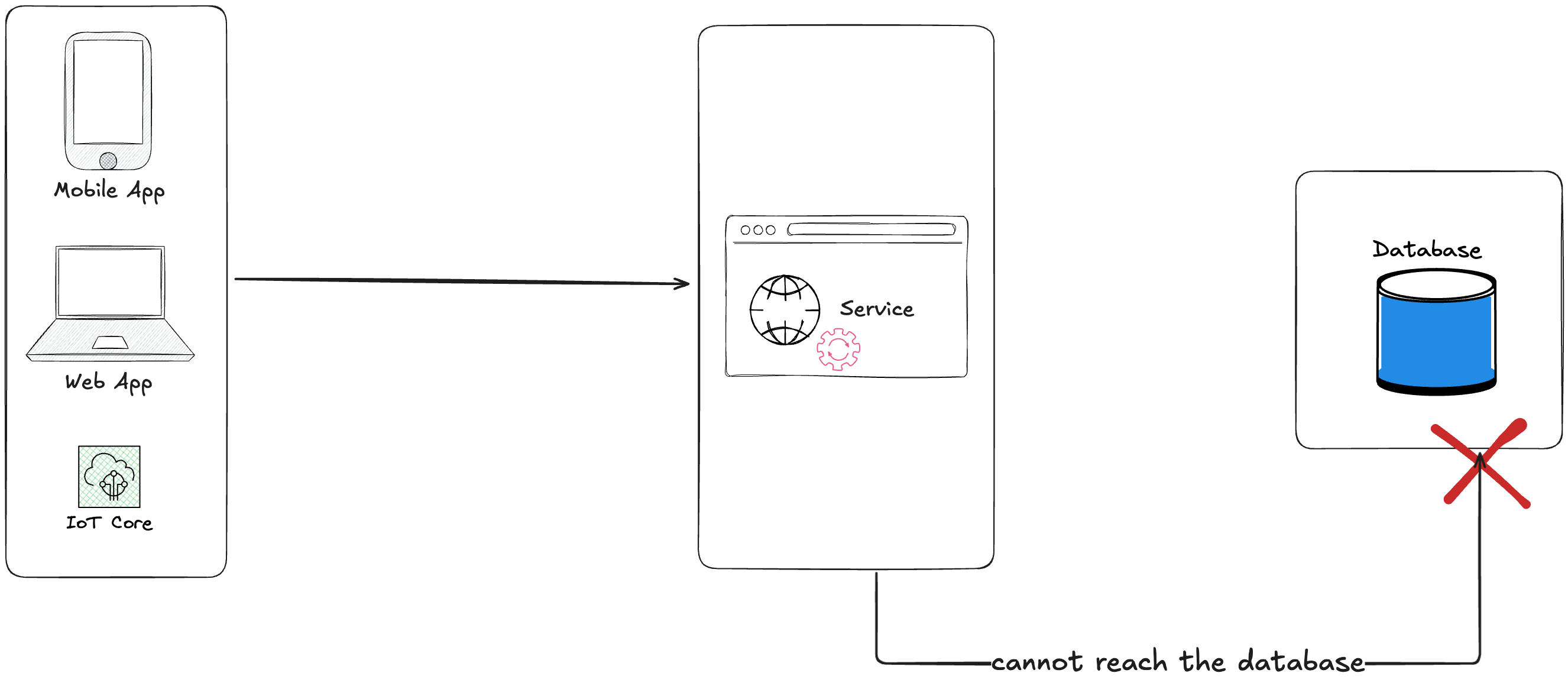
Unavailable access to your data can have significant impact on your business activities, revenue and reputation. It's important to understand the most common root cause of database failures.
Replication Lag & Failover Issues
Schema Migrations Gone Wrong
Misconfigurations (DNS, Networking, Permissions)
Lack of Backups & Disaster Recovery Planning
Planning for these scenarios during the design phase is essential. There are 2 main metrics to implement in order to lower the risks if an incident happens :
Recovery Time Objective (RTO) : How long it takes to restore the database in case of failure ?
Recovery Point Objective (RPO) : How much data can you loose (the retention of your backups : minutes, days, months, years) ?
There are several database recovery strategies :
| Database recovery strategies | RTO (Recovery Time Objective) | RPO (Recovery Point Objective) | Cost |
|---|---|---|---|
| Full Backup (Daily/Weekly) | Hours to days (restore from backup) | Up to last backup (24h+ data loss possible) | $ (Cheap) |
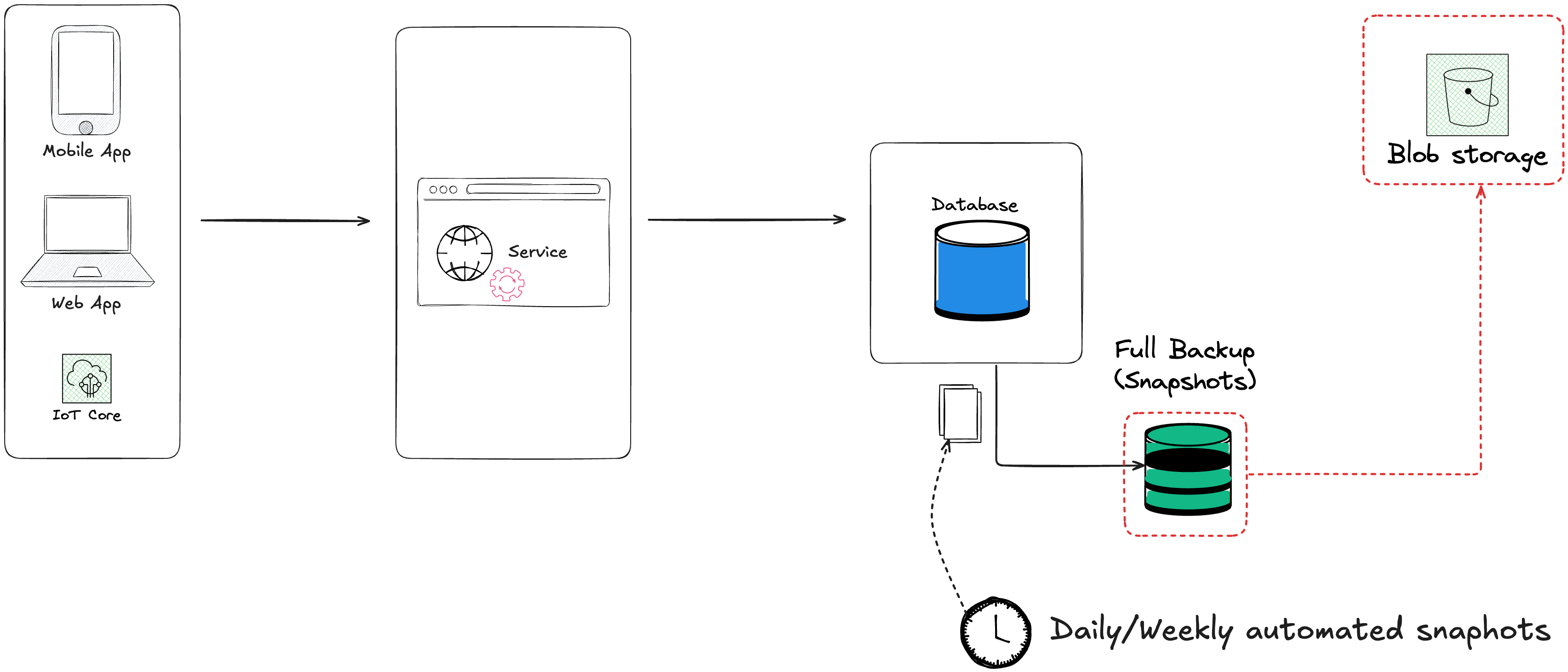
| Database recovery strategies | RTO (Recovery Time Objective) | RPO (Recovery Point Objective) | Cost |
|---|---|---|---|
| Asynchronous Replication (Active-Passive) | Seconds to minutes | Seconds to minutes (small lag possible) | $$ (higher cost) |
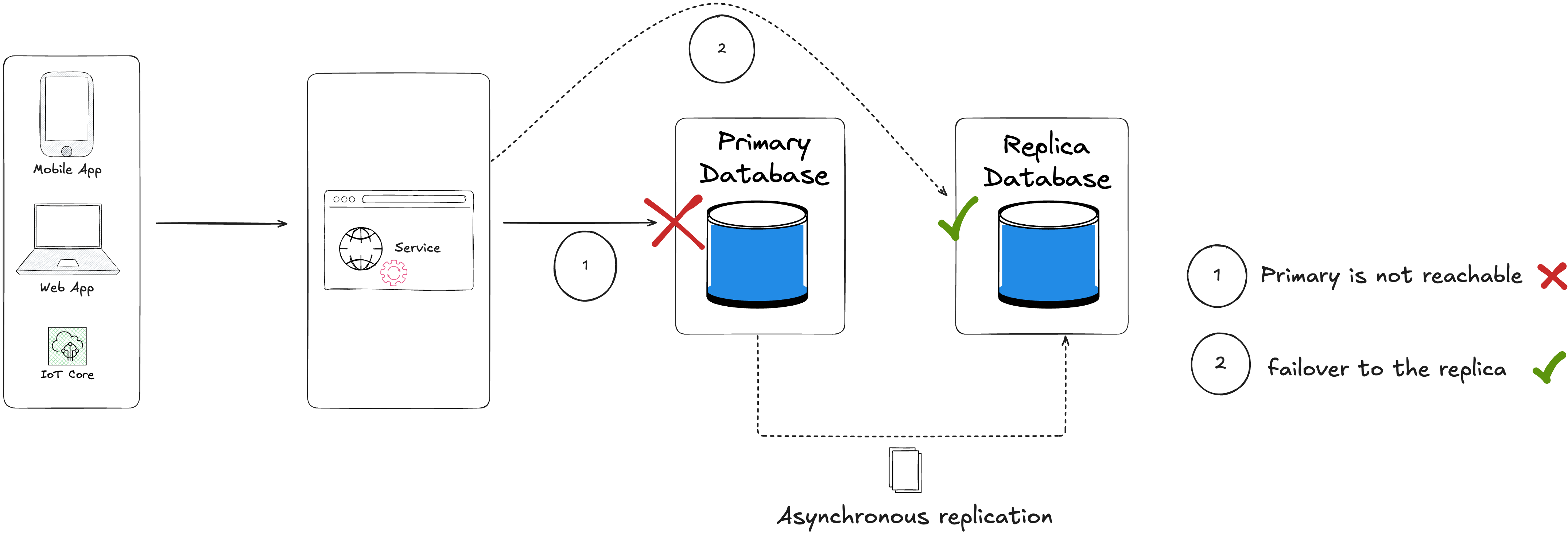
| Database recovery strategies | RTO (Recovery Time Objective) | RPO (Recovery Point Objective) | Cost |
|---|---|---|---|
| Synchronous Replication (Active-Standby) | Seconds to minutes (automatic failover) | Zero (no data loss) | $$$ (Very expensive) |
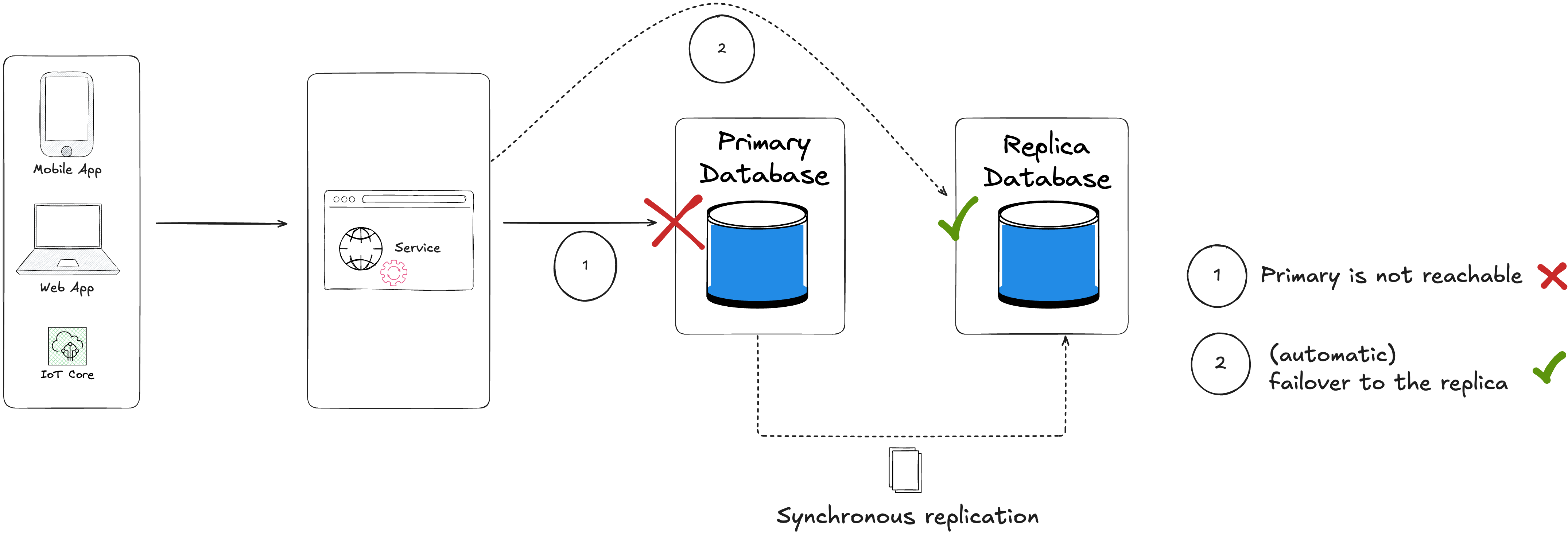
Here are the recommended RTO and RPO per industry :
| Type of workload | Recommended RTO (Recovery Time Objective) | Recommended RPO (Recovery Point Objective) | Sources |
|---|---|---|---|
| Mission-critical (tier-1) applications | ≤ 15 minutes | “near-zero” | https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-of-on-premises-applications-to-aws/recovery-objectives.html |
| Important but not mission critical (tier-2)” apps | ≤ 4 hours | ≤ 2 hours | https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-of-on-premises-applications-to-aws/recovery-objectives.html |
| Less critical applications | 8-24 hours | 4 hours | https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-of-on-premises-applications-to-aws/recovery-objectives.html |
Real-world cases where lack of RPO/RTO strategies cost companies revenue
| Company | Incident Description | Revenue / Impact | Root Cause / Lessons | Sources |
|---|---|---|---|---|
| Ma.gnolia (2009) | Production database lost; backups incomplete/unrecoverable. | Complete data loss; company shut down. | No RPO/RTO strategy; backups not tested, no recovery plan. | More details |
| Code Spaces (2014) | Attackers deleted databases and backups on AWS; recovery impossible. | 100% business loss; company shut down within days. | No tested disaster recovery plan, no offsite/immutable backups (RPO/RTO failure). | More details |
| Delta Airlines (2016) | Power outage + backup system failure caused DB corruption; IT systems down. | 2,300+ flights canceled; global operations disrupted for 3 days; ~$150 million loss. | Disaster recovery didn’t meet RTO; systems took too long to restore. | More details |
| British Airways (2017) | Data center power issue led to DB corruption for check-in/reservation systems. | 75,000 passengers stranded; days of disruption; £80+ million in costs. | Lack of resilient recovery plan to meet business-critical RTO for databases. | More details |
How can I limit the access to the database ?
The database stores all kind of data, you probably want to limit who can have access to the database, especially if you store sensitive and critical information. Understanding who should have access is a first step, is it a service account or a human user ?
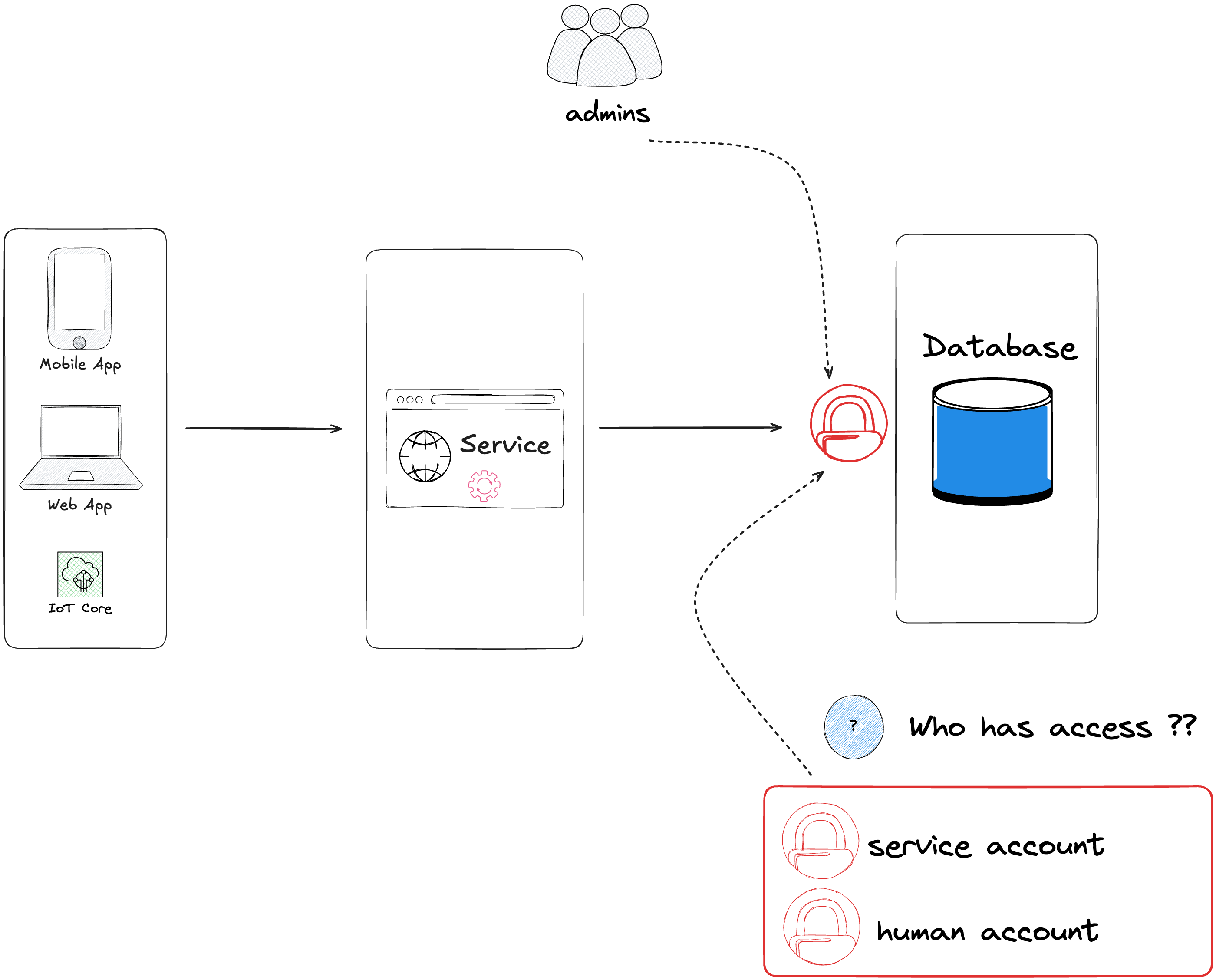
To enhance the access to the database, it might be a good practice to limit the network access, authorizing only requests from specific subnet (usually backend subnet), and use security group to authorize incoming traffic on the database target TCP port from restricted sources (IP address, group of servers, etc..)
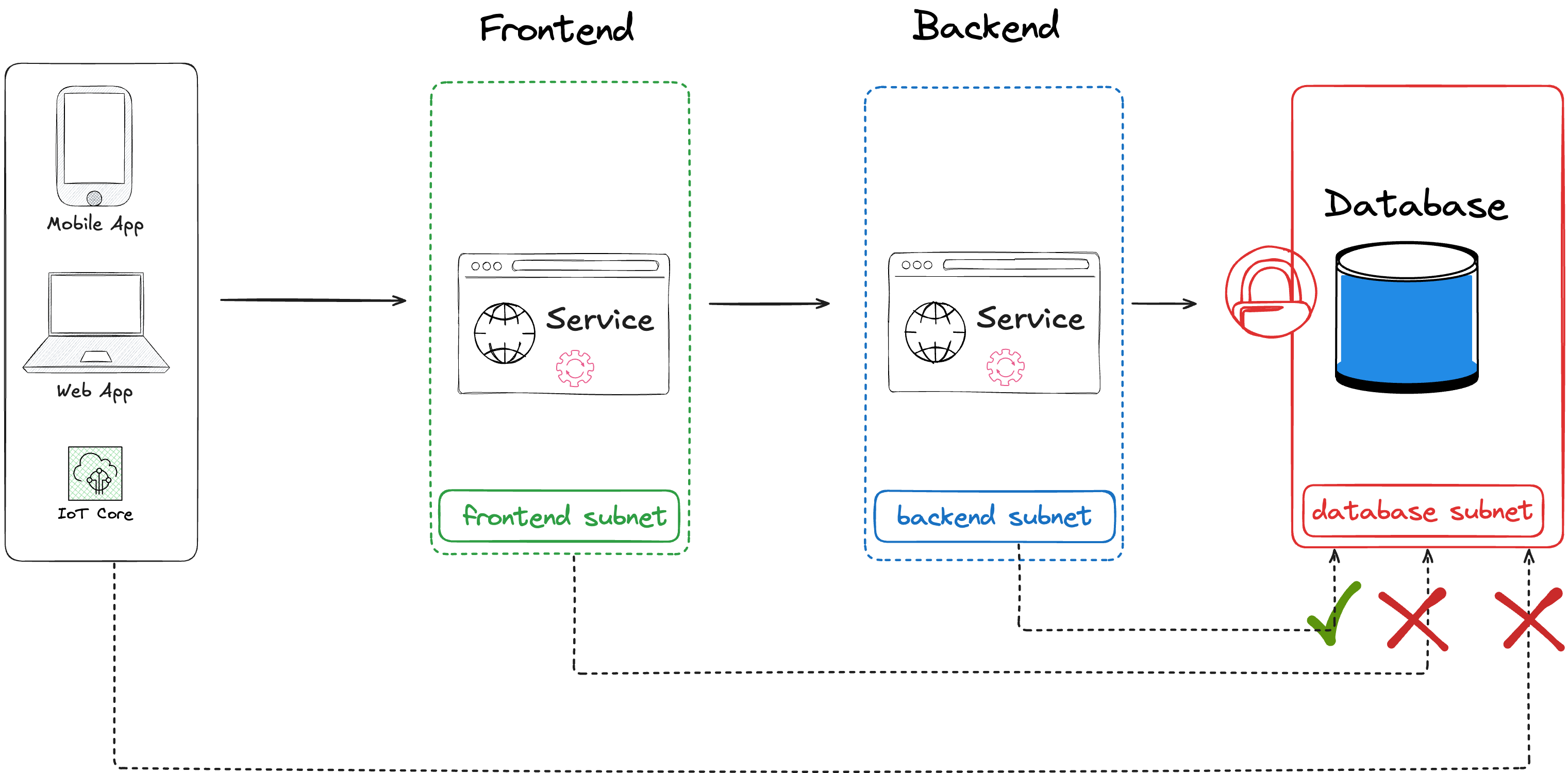
Once the user or service account authenticated, it's important to limit the actions on the database (CREATE DATABASE, CREATE TABLE, UPDATE, ...). Best practices include assigning the least privileges (roles to perform only restricted operations on the database). Credentials can be stored in a secrets store (secrets manager, key vault, ..), with password rotation to enhance security.
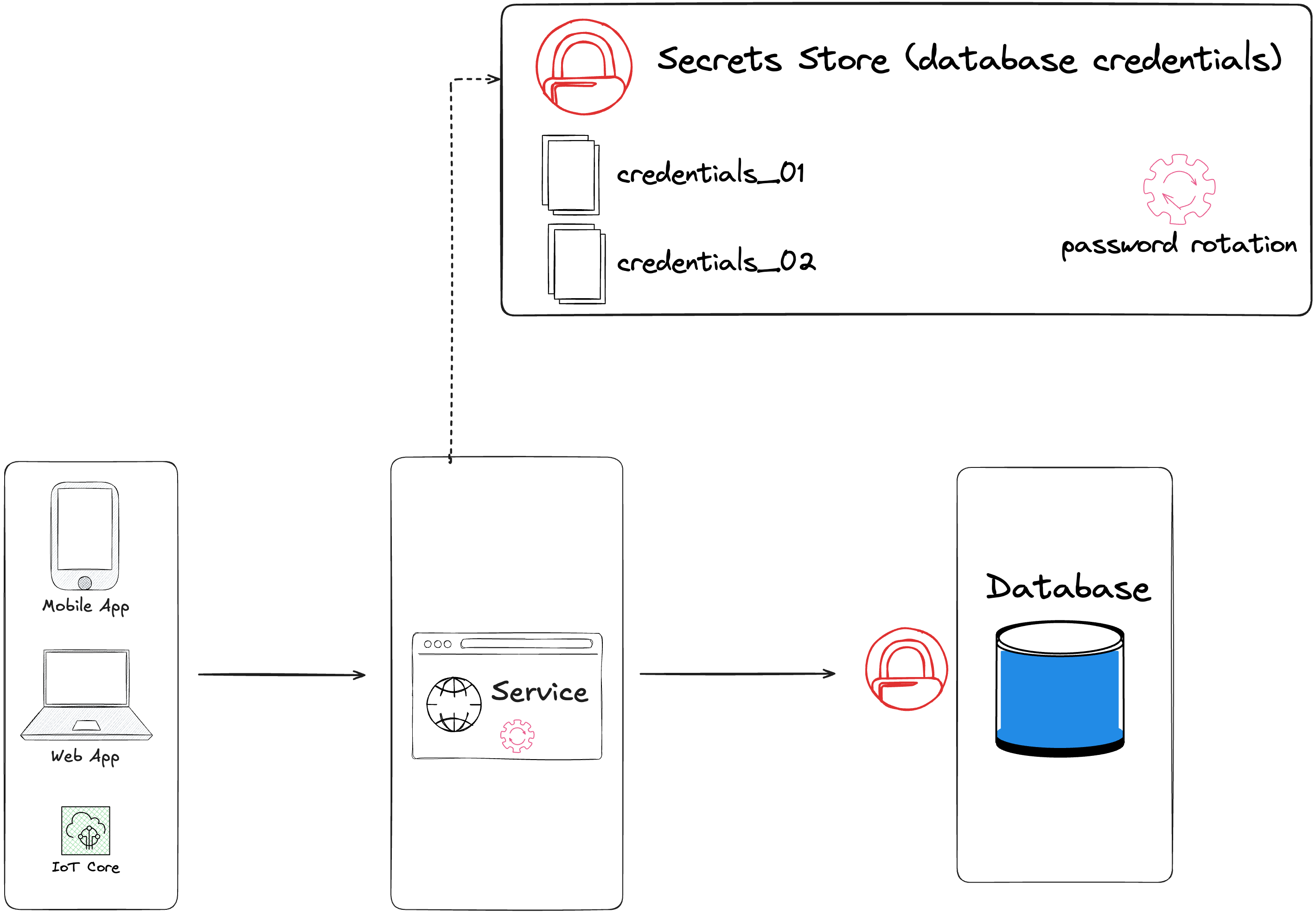
Breaches due to credentials
| Company | Incident Description | Data Compromised / Key Metrics | Root Cause / Lessons | Sources |
|---|---|---|---|---|
| Uber | Attackers accessed Uber’s AWS database using credentials found in a GitHub repository. | 57 million users and 600,000 drivers’ personal information. | Storing credentials in version control; importance of secret management. | More details |
| Capital One | Attacker exploited a misconfigured AWS IAM role using stolen credentials to access cloud storage. | 106 million customer records in the U.S. and Canada. | Excessive permissions in IAM roles; need for credential rotation and monitoring. | More details |
| Dropbox | Stolen employee password (from a LinkedIn breach) was reused to access Dropbox employee accounts, leading to data exposure. | 68 million user accounts affected. | Highlights the dangers of password reuse and lack of MFA. | More details |
Do I need to secure the data in transit ?
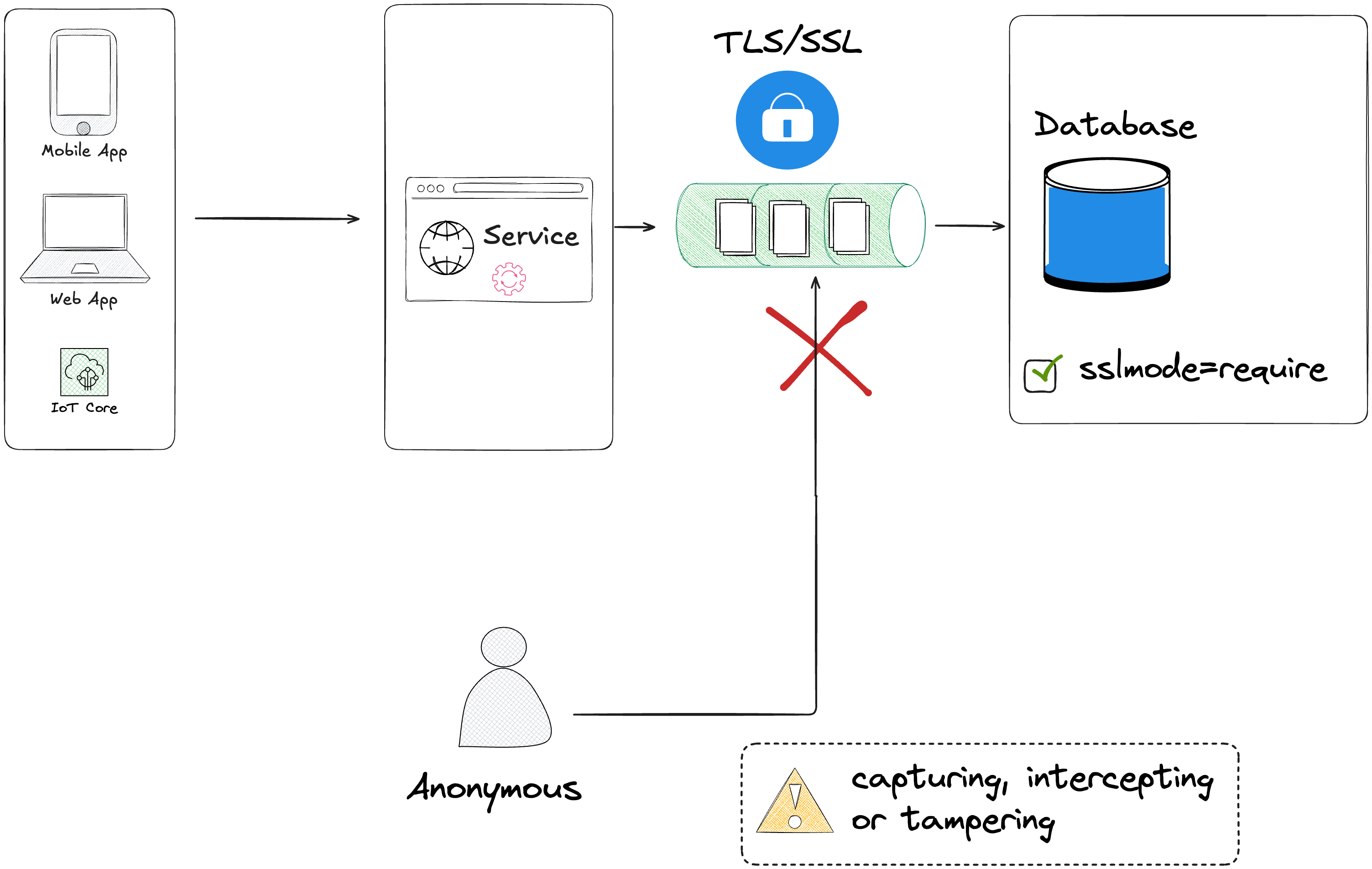
It's a good practice to secure the traffic between your applications and the database. By enabling SSL mode in your database, you lower the risks, and prevent anonymous connections from intercepting or tampering the traffic sent to the database.
Also if you need to follow these regulations (GDPR, HIPAA, PCI DSS, SOX, HDS), it's required to enable encryption to secure the data in transit.
GDPR (General Data Protection Regulation) : A regulation by the EU that governs how organizations collect, process, store, and share personal data of individuals in the EU
HIPAA (Health Insurance Portability and Accountability Act) : sets standards for how healthcare organizations, insurers, and their business partners handle Protected Health Information (PHI) — any data that can identify a patient and relates to their health, treatment, or payment for care
PCI DSS (Payment Card Industry Data Security Standard) : a global security standard created to protect cardholder data (credit/debit card information) and reduce payment fraud. Applies to any organization that stores, processes, or transmits payment card data.
HDS (Hébergement de Données de Santé) : french regulation, It requires that healthcare-related personal data (patient records, medical history, test results, etc.) be stored and processed only by certified Health Data Hosts
Enabling SSL mode on your database does add CPU overhead for encryption and decryption. One option to prevent more load on your CPU is to use connection pooling.
Connection pooling is cache of open database connections that your application can reuse instead of creating a new one each time, reducing latency and CPU load.
Using benchmark to measure if your database performs better with or without connection pooling is recommended.
Breaches due to not protecting data in transit
| Company | Incident Description | Data Compromised / Key Metrics | Root Cause / Lessons | Sources |
|---|---|---|---|---|
| Heartbleed (OpenSSL) | The Heartbleed vulnerability in OpenSSL allowed attackers to read memory, exposing data that was assumed to be encrypted in transit. | Usernames, passwords, session keys, and sensitive application traffic (Yahoo confirmed user credential leaks). | Flawed TLS implementation; always patch crypto libraries and enforce TLS properly. | More details |
| TJX / TJ Maxx | Attackers exploited weak WEP encryption between store POS systems and backend databases to intercept card data. | 94 million credit card numbers stolen. | Outdated WEP protocol; always use strong encryption standards (TLS 1.2/1.3, WPA2+). | More details |
| Equifax | Attackers exploited unpatched Apache Struts, intercepting unencrypted traffic between apps and backend databases. | ~147 million personal records including SSNs and financial data. | Lack of TLS enforcement and unpatched software; highlights need for TLS and regular patching. | More details |
| Marriott / Starwood Hotels | Attackers monitored unencrypted internal traffic between reservation systems and databases for years. | 500 million guest records (passport numbers, PII, payment data). | Legacy systems lacked encryption in transit; internal traffic must also be encrypted. | More details |
How can I secure the database at rest ?
You've just secured the traffic sent to your database. But how about the data stored in your database ? It's a good practice to encrypt the data at rest, at the disk level, using key management system. Backups should also be encrypted to prevent unauthorized access to the data.
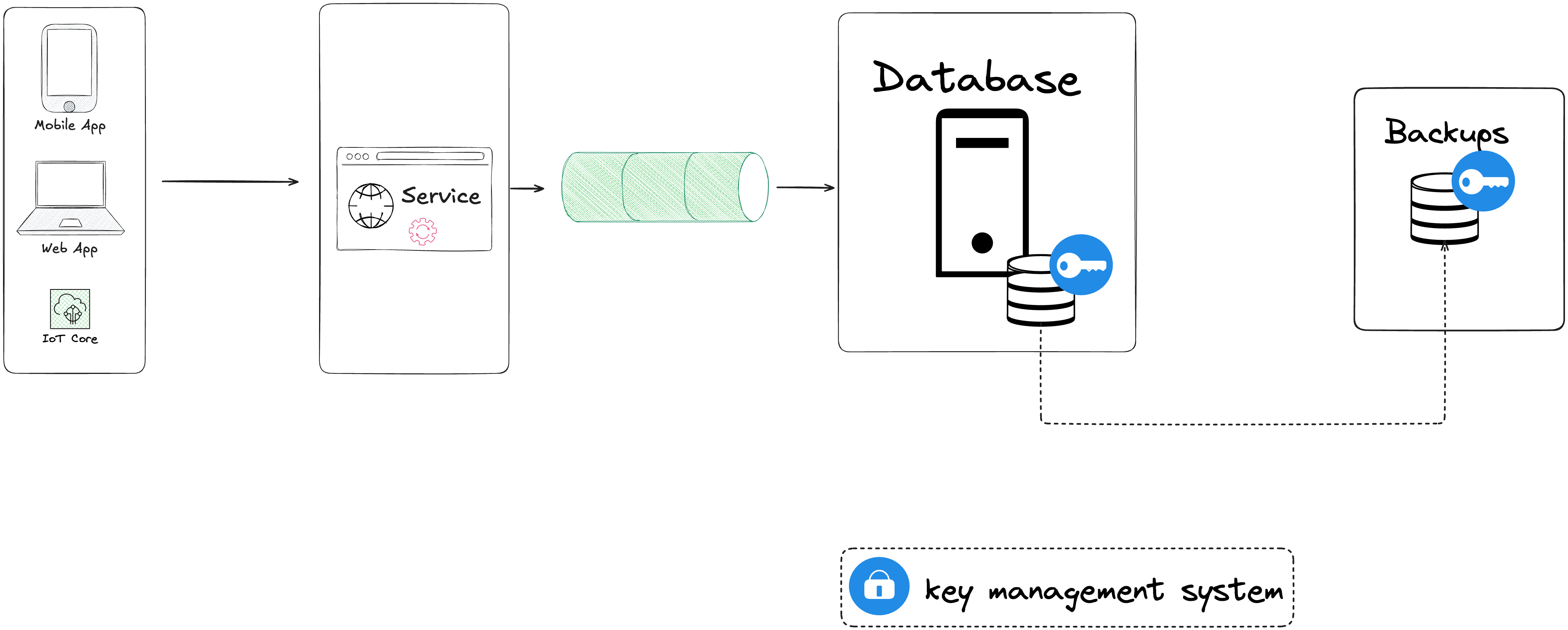
Breaches due to not protecting databases at rest
| Company | Incident Description | Data Compromised / Key Metrics | Root Cause / Lessons | Sources |
|---|---|---|---|---|
| Health Net | Lost unencrypted hard drives containing sensitive medical data. | ~1.9 million patient records. | No encryption on physical storage; highlights importance of database encryption at rest. | More details |
| US Veterans Affairs | Stolen laptop contained an unencrypted database of veterans’ information. | ~26.5 million personal records. | No encryption on endpoint databases; lesson: enforce full-disk and DB encryption. | More details |
| Ashley Madison | Hackers stole entire unencrypted database, with weak password storage and payment details. | ~32 million user records leaked. | Poor hashing/encryption; highlights need for strong cryptography at rest. | More details |
| Desjardins Group | Employee exfiltrated internal unencrypted databases containing customer information. | ~4.2 million customer records. | Lack of encryption at rest made insider theft possible; highlights need for DB encryption and monitoring. | More details |
What happens if I need to scale the database ?
You may have to handle more load on your database (traffic, queries, ..), and to prevent any performance degradation, you have some options to scale your database. Usually there are 2 scaling strategies :
Vertical Scaling
Horizental Scaling
Vertical scaling is the first option if you want to handle more traffic, it's easier to implement, you just have to add more resources (more cpu, memory or faster disk and bandwitdh).
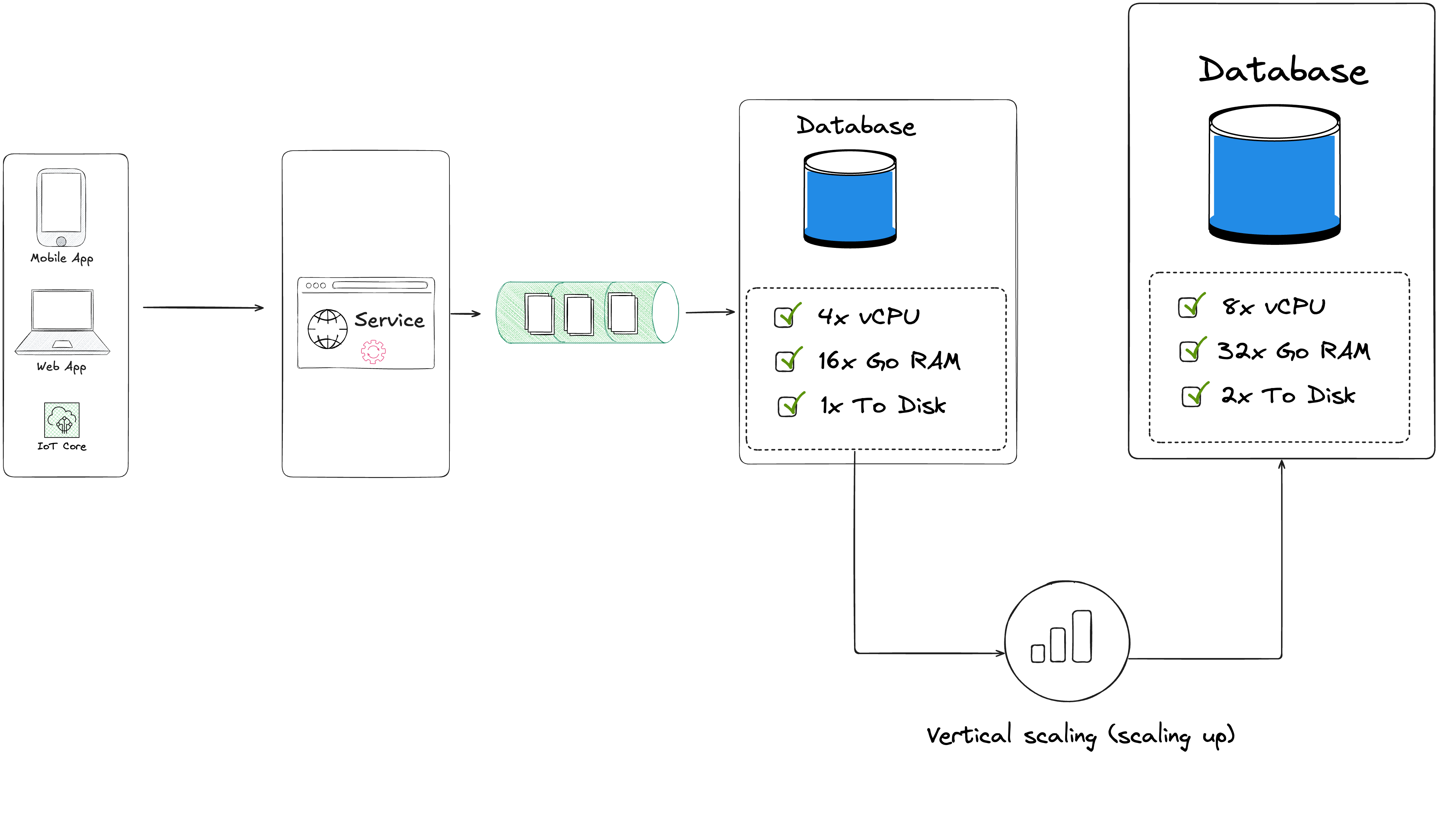
Horizental scaling is a little bit more complex to implement. You need to add replicas node which handle only read-only requests. All the write queries goes to the primary DB, and the read queries to the replicas nodes to distribute the traffic.
There are several other options you can implement to handle more traffic
Load balancers or databaes proxies : helping you redistribute the traffic (connection pooling)
Autoscaling : cloud managed databases offer options to scale automatically your database.
Sharding and Partionning : For heavy workloads and traffic, you may need at some point to use sharding and partionning, the goal is to split your database in multiple smaller "datasets". It's usually quite complex to implement.
Use cases with scaling-related database outage/revenue loss
| Company | Incident Description | Revenue / Impact | Root Cause / Lessons | Sources |
|---|---|---|---|---|
| Twitter (Fail Whale Era) | Frequent outages due to MySQL write bottlenecks as user growth exploded. | Millions in lost ad revenue and user churn. | Vertical scaling limits reached; need for sharding, caching, and horizontal scaling. | More details |
| Amazon Prime Day (2018) | Surge of traffic overloaded internal databases and order systems. | Estimated $72–100 million in lost sales during downtime. | Peak load exceeded DB scaling capacity; need for proactive load testing and auto-scaling. | More details |
| Roblox (2021) | A database growth issue caused cascading failure across backend (MongoDB-based). | 3 days offline; tens of millions in lost revenue + developer payouts delayed. | Poor handling of DB growth; need for partitioning, replication, and distributed DB design. | More details |
| Facebook (early scaling) | Multiple outages due to MySQL bottlenecks and insufficient caching in early years. | Millions in lost ad revenue during downtime. | Single-node bottlenecks; drove adoption of sharding and memcached at massive scale. | More details |
| GitHub (2012) | Database cluster failover led to prolonged downtime; writes bottlenecked on a single master. | Lost paid subscriber revenue and SLA penalties to enterprise customers. | Weak HA setup; need for resilient replication and multi-master designs. | More details |
| Ticketmaster (various) | Ticket sales portals crashed during high-demand events due to backend DB bottlenecks. | Hundreds of millions in lost ticket sales and refunds (e.g., Taylor Swift 2022). | Insufficient scaling for sudden spikes; need elastic DB scaling and load balancing. | More details |
How can I monitor the activity on the database ?
Let's assume your application is running smoothly, everything works just fine. Users have access to every features of your application and can perform all operations. Then suddenly, you start getting emails from 1 frustated user, furious about their experiences, seems like some features didn't work fine, or there is a huge latency when performing some actions. But it doesn't end there, more and more users start to send emails with their bad experiences.
You're shocked as you didn't notice any sign of performance degradation, your application seems to work just fine. You then realize by investigating, that there are a lot of warnings, and errors in the logs.
This experience shows the importance of monitoring the activity of your infrastucture, to anticipate and prevent in advance your users/customers from having bad experiences.
It's then crucial to understand which metrics can help your understand what's happening on your database and if you should get any alerts as soon as some threshold are met.
| Monitoring Objectives | Description | Core metrics to collect | Alerts and thresholds |
|---|---|---|---|
| Availability & health |
Is the database up and reachable ? |
Examples of metrics on PostGreSQL : pg_up, pg_connections, pg_stat_activity_count |
Examples with PostgreSQL (pg_up == 0) |
| Performance |
Is there any latency to reach the database ? Are the queries slow ? |
Total queries/sec and transactions/sec 95th/99th percentile query latencies Slow queries count |
connections >= 90% of max_connections (Connections near max) query running > 5–15 min (Long running query) slow_queries / total_queries > 1% over 5m (Slow query rate) |
| Resources & capacity |
Is the database server capacity overloaded ? What is the status of the resources consumption (CPU, Memory, Disk usage, Disk latency, network I/O) |
CPU Memory Disk usage, Disk Latency |
CPU > 85% for 5m Memory > 85% for 5m Disk usage > 80% |
| Errors & Fault |
What are the errors in the logs ? This should indicate the failed queries, connection errors |
Error Logs |
Error rate (failed queries / total queries) |
| Security and Audits |
Logins (successful & failed) Privilege changes Suspicious exports |
failed logins new user creation privilege escalations unusual export activity |
failed login attempts spike (possible brute force) |
| Replication and Bakcups |
Replication lag Backup success WAL/redo lag |
last successful backup time backup duration restore test results |
last_backup_time older than expected retention window lag > 10s (or > 60s depending on app) |
Use cases with revenue loss from not monitoring DB activity
| Company | Incident Description | Revenue / Impact | Root Cause / Lessons | Sources |
|---|---|---|---|---|
| Target (2013) | Attackers exfiltrated payment card data; suspicious DB queries went unnoticed. | ~$162 million in costs (settlements, fines, legal). | Lack of real-time monitoring for abnormal database reads and exports. | More details |
| Sony Pictures (2014) | Attackers had weeks of DB access; leaked unreleased films, scripts, employee data. | Hundreds of millions in lost revenue and IP theft. | No database query monitoring or large export detection. | More details |
| Equifax (2017) | Attackers exploited Struts flaw, accessed DBs, and stole 147M personal records. | >$1.4 billion in breach costs + stock value drop. | No alerts on abnormal DB access to sensitive PII. | More details |
| Capital One (2019) | Misconfigured firewall allowed DB access; 100M+ records exfiltrated without detection. | $190 million in settlements + regulatory fines. | No alerts for massive data pulls from databases. | More details |
| Desjardins Group (2019) | Insider exfiltrated data of 9.7M members over months without being flagged. | Hundreds of millions in costs, lawsuits, and brand damage. | Lack of insider threat monitoring and alerts for unusual exports. | More details |
| Shopify (2020) | Rogue employees accessed merchant DBs and stole customer transaction details. | Reputational harm, legal expenses, and merchant trust loss. | Inadequate monitoring of privileged employee queries on live DBs. | More details |
Are there any hidden costs I should worry about ?
During the design phase, you should define a cost model and forecasting plan for operating your infrastructure in the cloud, so you understand expected expenses and the trade-offs of architectural decisions
Your cloud cost architecture plan often includes the following :
Expected baseline costs (compute, storage, networking)
Your assumptions on the growth and if your infrastructure scales
The cost tradeoffs of the design decisions (should you implement a multi-AZ, a single-AZ, reserved vs on-demand, open-source vs commercial , etc ...)
There are always hidden costs while operating your cloud database :
| Cost Category | Use Cases | Prevention | Sources |
|---|---|---|---|
| Backup / Snapshot Storage & Retention |
You enabled snapshots on your database, and you don't have a clear retention policies There are copies of your snapshots cross-region |
Snapshot storage are charged per GB/month, unecessary snapshots should be deleted Set retention policies |
More details |
| Data Transfer (Cross-AZ / Cross-Region) |
You application read from database (read-replicas) in another AZs or in another region There is traffic (egress) sent to Internet, We tend to underestimate the volume of data (egress/ingress). |
Collect metrics and setting alerts to prevent the billing to increase unexpectedly. |
More details |
| Idle / Non-Production Environments & Orphaned Resources |
You run multiple environnements (staging, dev, production), but not all the environnements needs to run 24/7 Snapshots remain after a DB deletion The database instance size absorb peaks but it's usually in idle (underutilized) |
Turn off resources in non critical environments (automatic shutdown off of instances, etc..) Right size the database instance type, benchmark if possible, optimize the queries if necessary |
|
| Monitoring, Logging, Metrics Retention |
You enabled multiple metrics, and detailed logs (audit logs, ddl events, etc ...) |
Track the volume of the logs ingested and the storage capacity costs (increase) |
Use cases with revenue loss due to hidden or unexpected costs
| Company | Incident Description | Revenue / Impact | Root Cause / Lessons | Sources |
|---|---|---|---|---|
| Pinterest (2017) | AWS costs spiked during holiday season due to massive unoptimized database and compute usage. | Margins squeezed by unplanned cloud spend during peak traffic. | Lack of monitoring and cost controls on scaling workloads. | More details |
| Adobe (2018) | Large unoptimized AWS workloads ran longer than intended, driving up cloud bills. | Tens of thousands in unplanned charges. | Lack of governance and auto-shutdown policies for workloads. | More details |
| Basecamp (2014) | AWS S3 costs surged due to inefficient data storage and backups. | Direct margin squeeze until re-architecture. | No cost monitoring on object storage growth. | More details |
| NASA JPL (2019) | AWS credentials exposed, attackers used resources for crypto-mining. | ~$30,000 in stolen compute costs. | No monitoring of abnormal API usage or sudden billing spikes. | More details |
| Snapchat (2017) | Google Cloud costs spiraled as user activity surged faster than infra optimization. | Losses of $2.2 billion in IPO year; cloud costs grew faster than revenue. | Poor forecasting and inefficient DB queries increased hidden costs. | More details |
| Multiple Orgs (2018–2021) | Misconfigured open databases exploited for crypto-mining workloads. | Tens of thousands in surprise compute bills. | No alerts on abnormal workloads or sudden cloud billing spikes. | More details |
Learning from real world experiences
Databases breaches and incidents happen all the time, 100% protection does not exist. Prestigious companies and firms have experienced security breaches despite having implemented tight security controls, it's important to learn from their experiences to understand how you can prevent these scenarios or at least lower the risks or the gravity if you experience a breach.
The goal is not to implement the latest security tools and think you're out of reach, it's better to implement a progressive and continuous protection, re-assess continuously your security posture, improve the protection of the weakest link in your infrastructure.
Here you can find the top root causes of database breaches :
Misconfiguration (Open Databases, Wrong ACLs,..)
Credentials (weak passwords, reused credentials, no password rotation, no MFA)
Zero-days /Supply Chain attacks
Provider/Partner attacks
Below is the summary of recent database breaches grouped by root cause :
| Root cause (ranked by frequency) | Example of breach | Year | Impact (record/people) | Why It happened | Sources |
|---|---|---|---|---|---|
| 1. Misconfiguration (Unprotected DBs / Poor Access Controls) |
Chinese Surveillance DB |
2025 |
~4 Billions |
Database left exposed, no password protection |
More details |
| 1. Misconfiguration (Unprotected DBs / Poor Access Controls) |
Microsoft/Apple/Google/PayPal DB leak |
2025 |
184 Millions |
Elasticsearch DB exposed without auth |
More details |
| 1. Misconfiguration (Unprotected DBs / Poor Access Controls) |
Texas General Land Office |
2025 |
44,485 people |
Access control misconfig allowed cross-user data view |
More details |
| 2. Credential Compromise / Weak Authentication |
23andMe |
2023-25 |
Dozens of orgs; AT&T, Ticketmaster, Santander, etc. |
Weak MFA/credential hygiene; compromised access |
More details |
| 2. Credential Compromise / Weak Authentication |
Kering / Gucci–Balenciaga |
2025 |
Millions of customers |
Hacker group “Shiny Hunters” stole customer DB creds |
More details |
| 3. Software Vulnerabilities / Supply Chain Exploits |
MOVEit Transfer Zero-day |
2023 |
~93–100 Millions people, 2700+ orgs of customers |
Zero-day exploited in widely used file transfer system |
More details |
| 3. Software Vulnerabilities / Supply Chain Exploits |
Latitude Financial |
2023 |
~14 Millions records |
Exploit in provider’s systems; details not fully disclosed |
More details |
| 4. Direct Cyberattacks / Service Provider Compromise |
Qantas Airways |
2025 |
~5.7 Millions customers |
Hackers gained access to customer DB |
More details |
| 4. Direct Cyberattacks / Service Provider Compromise |
Miljodata |
2025 |
~1.5 Million people |
IT provider cyberattack leaked sensitive records |
More details |
Top 10 recurrent database production issues
Everything breaks all the time. Databases can break in production, it's critical to understand the main sources of these issues and anticipate any actions to prevent and reduce their impact and cost.
| # | Database Issue | Real-World Example | Business Impact | Estimated Loss | Root Cause | Sources |
|---|---|---|---|---|---|---|
| 1 | Connection Leaks | Barclays IT Outage (Jan 2025) – mainframe software bug impacted core banking access. | Widespread service unavailability, frustrated customers. | Up to £12.5M compensation | Software bug, improper connection handling | Yahoo Finance |
| 2 | Slow Queries / Missing Indexes | Asana Outages (Feb 2025) – excessive logging caused DB and downstream service slowdowns. | Multi-hour service disruption, productivity losses | Millions in lost productivity | Unoptimized queries and logging infrastructure overload | |
| 3 | Deadlocks | Delta Air Lines Outage (Jul 2024) – software update failure triggered system crashes. | Flight delays, operational disruption | $500M estimated losses | Faulty software update, unhandled concurrent operations | New York Post |
| 4 | Lock Contention | Co-op Cyberattack (Apr 2025) – operational systems disrupted across 2,300 stores. | Store outages, supply chain delays | £275M lost revenue | Cyberattack causing DB and system resource contention | Acronis |
| 5 | Schema Changes in Production | GitLab (2017) – schema migration failure led to downtime. | Service unavailable, partial data loss | 6 hours of customer data lost, reputational damage | Uncontrolled migration, no rollback strategy | GitLab Blog |
| 6 | Data Corruption | Delta Air Lines Outage (Jul 2024) – software errors corrupted system data. | Operational disruption, loss of customer trust | $500M estimated losses | Faulty update, unvalidated data integrity | New York Post |
| 7 | Replication Lag | Asana Outages (Feb 2025) – excessive logging caused replica delays. | Inconsistent UX, service errors | Millions in productivity lost | Async replica lag under heavy logging load | |
| 8 | Unsecured Databases | Co-op Cyberattack (Apr 2025) – exposed internal DBs led to operational disruptions. | Data theft risk, system downtime | £275M lost revenue | Lack of authentication, open access points | Acronis |
| 9 | Backup & Restore Failures | GitLab (2017) – untested backups caused permanent data loss during outage. | Loss of customer trust, reputational damage | Priceless, indirect revenue loss | Unverified backup processes, no RPO/RTO drills | GitLab Blog |
| 10 | Capacity & Scaling Issues | Co-op Cyberattack (Apr 2025) – DB overload caused operational outages. | Store closures, supply chain disruption | £275M lost revenue | No auto-scaling, underestimated peak load | Acronis |